
Choosing the Right Key Type for Your Tables: A Comparison of Primary, Foreign, and Unique Keys
Understanding the Pros and Cons of Each Key Type to Optimize Your Database Design

When designing a database, choosing the right type of key for each table is essential to ensure data accuracy and consistency. Primary, foreign, and unique keys are the three main types of keys that can be used in a database to enforce data integrity. In this article, we'll take a closer look at each of these key types and provide code examples and screenshots to help you understand their differences.
Primary Keys
A primary key is a unique identifier for each row in a table. It is used to ensure that each row can be identified uniquely and also to enforce referential integrity. The primary key must be unique and not null for each row in the table. It can be a single column or a combination of columns. Here's an example of how to create a primary key in T-SQL for Microsoft SQL Server:
CREATE TABLE customers (
customerId INT PRIMARY KEY,
name VARCHAR(50),
age INT
);In this example, the "customerId" field is designated as the primary key for the "customers" table.
Something else to keep in mind is when a primary key is created on a table, by default a clustered index is created using that column as the index key.
I went and created the above table in my local SQL Server and here we can see the primary key and clustered index made on the table:
Foreign Keys
A foreign key is a field or combination of fields in one table that refers to the primary key or unique key of another table. It is used to establish relationships between tables and enforce referential integrity. When a foreign key is defined, SQL Server checks to ensure that the referenced primary/unique key exists in the referenced table before allowing a new record to be added or modified. Here's an example of how to create a foreign key in T-SQL for Microsoft SQL Server:
CREATE TABLE orders (
orderId INT PRIMARY KEY,
customerId INT,
FOREIGN KEY (customerId) REFERENCES customers(customerId)
);In this example, the "orders" table has a foreign key that references the primary key (customerId) of the "customers" table. There is also a primary key on the "orderId" column for the "orders" table.
After running the above code locally, we can see that the primary key and foreign key are created. The clustered index is also created due to the primary key:
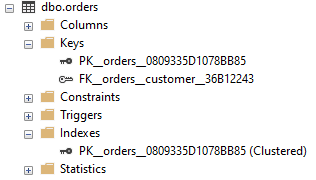
Unique Keys
A unique key is a field or combination of fields in a table that ensures uniqueness across all rows. Unlike primary keys, unique keys can allow null values. However, keep in mind that a unique key will only allow for a single NULL value, not multiple, into a column. Here's an example of how to create a unique key in T-SQL for Microsoft SQL Server:
CREATE TABLE users (
userId INT PRIMARY KEY,
userName VARCHAR(50) UNIQUE,
email VARCHAR(100) UNIQUE,
password VARCHAR(100)
);In this example, a primary key is created on the "userId" column and both the "userName" and "email" fields are designated as unique keys for the "users" table.
Unique keys create unique non-clustered indexes by default on their respective columns.
After running the above CREATE statement locally, this is what I can see:
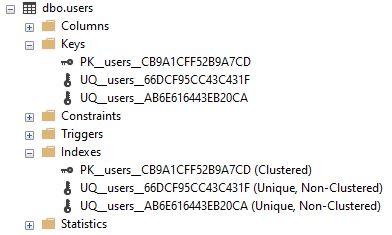
There are two unique non-clustered indexes created due to the two unique keys that were created on the table. The unique non-clustered indexes help enforce the uniqueness of the columns that the unique key is on.
Conclusion
Choosing the right type of key for each table is critical for maintaining data integrity and accuracy in a database. Primary keys ensure each row can be identified uniquely and creates a clustered index that doesn’t allow NULL values, foreign keys establish relationships between tables, and unique keys enforce the uniqueness of data by creating unique non-clustered indexes which only allow for a single NULL value.
Next week, I will talk about a workaround where we can allow multiple NULL values in a UNIQUE key column, even though by default we can only allow a single NULL value.
See you next Sunday!
Insightful