
Difference between TRUNCATE, DROP and DELETE
Deleting Data in SQL: Understanding the Nuances of TRUNCATE, DROP, and DELETE Commands

When it comes to managing a database, there are various commands that can be used to remove data from tables. Three of the most commonly used commands for deleting data in SQL are TRUNCATE, DROP, and DELETE. While they all seem to serve a similar purpose, there are crucial differences between them. In this article, we'll take a closer look at TRUNCATE, DROP, and DELETE, and explore their unique features and potential risks.
TRUNCATE:
The TRUNCATE command is used to remove all rows from a table, effectively wiping out all data in a table. When TRUNCATE is used, the table structure remains intact, and any constraints, triggers, or indexes defined on the table are also preserved. Since TRUNCATE does not log each row deleted, it is significantly faster than DELETE, especially when working with large tables. However, it cannot be undone, and any data deleted by TRUNCATE cannot be recovered.
To illustrate, let's create a table called "employees" with some sample data in it:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT NOT NULL,
salary INT NOT NULL
);
INSERT INTO employees VALUES
(1, 'Rashmi', 26, 1000000),
(2, 'Rae', 38, 70000),
(3, 'Jaedon', 7, 90000),
(4, 'Dilani', 38, 55000);Let’s have a look at the table when queried.
Query:
SELECT *
FROM employeesResults:
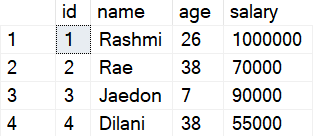
Now to truncate the table "employees", we would use the following command:
TRUNCATE TABLE employees;After running the TRUNCATE statement, we then query the table again to view the contents of the table.
Results from the earlier SELECT statement:
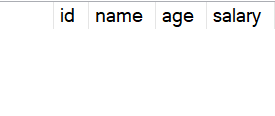
As you can see, the table has no rows. It’s completely empty.
One important thing to note about TRUNCATE is that it resets the identity column of the table. The identity column is a column that automatically generates unique values for each row inserted into the table. When you truncate a table, the identity column is reset to its seed value (usually 1), and the next value that is generated will be the seed value plus 1.
DROP:
The DROP command is used to remove an entire table, including its structure, data, and any constraints, triggers, or indexes defined on it. Once a table is dropped, it cannot be recovered, so it should be used with caution. DROP is typically used when you no longer need a table, or if you need to start over with a new table structure.
To illustrate, let's drop the "employees" table we created earlier:
DROP TABLE employees;If I try and query the table "employees" now, I get the below error message:

This error message means that SQL Server doesn’t recognise a database object named "employees". This is because the table and all its metadata were removed by the DROP command.
DELETE:
The DELETE command is used to remove rows from a table based on a specified condition. Unlike TRUNCATE, DELETE logs each row deleted, which can slow down the process when working with large tables. However, it allows you to selectively remove data from a table, rather than wiping out all data at once. Like TRUNCATE, DELETE preserves any constraints, triggers, or indexes defined on the table.
To illustrate, let's delete all employees over the age of 30 from our "employees" table:
DELETE FROM employees WHERE age > 30;Results:

As you can see rows where the age was greater than 30 were deleted from the table.
Also to note, DELETE leaves the identity value intact. So DELETE does not reset the identity column in a table.
In conclusion, TRUNCATE, DROP, and DELETE are all useful commands for removing data from a database. However, it is important to understand their distinct features and use cases to ensure that you are using the appropriate command for the task at hand.
See you guys next Sunday!
Thank you sir.. clearly understand the Truncate, delete, drop commands in very easy way with examples.
Insightful