
How to Remove Duplicates using SQL?
If you work or aspire to work in data, you will soon be tasked with removing duplicated data. Let's see how we can resolve it.

Data quality issues are a dime a dozen in the data world. It is paramount that you get comfortable removing duplicates.
Below I have created a script for you guys to try the examples I will be discussing later on in this post. The below script will create the table I will be using for my examples, feel free to follow along and use the script on SSMS and on your local SQL Server instance.
DROP TABLE IF EXISTS dbo.Orders;
CREATE TABLE dbo.Orders(
orderId int,
orderDate Date,
shippedDate Date,
shippedCountry nvarchar(50)
)
INSERT INTO dbo.Orders VALUES
(1,'2017-07-04','2017-07-16','France')
,(2,'2017-07-05','2017-07-10','Germany')
,(2,'2017-07-05','2017-07-10','Germany')
,(3,'2018-07-22','2018-07-31','Brazil')
,(3,'2018-07-22','2018-07-31','Brazil')
,(3,'2018-07-22','2018-07-31','Brazil')
,(4,'2018-07-18','2018-07-25','USA')
,(5,'2018-11-01','2018-11-14','India')
After creating the Orders table, it should look something like this:
SELECT *
FROM dbo.Orders
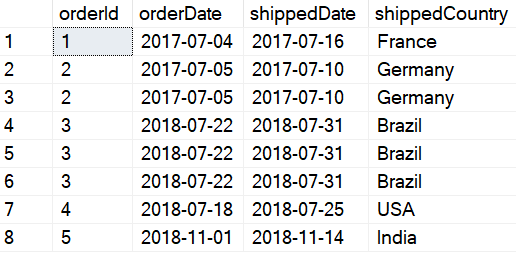
Now we have duplicates for rows with an orderId of 2 and 3. Our job is to remove those duplicates from this table.
First, let’s write up a query that can identify the duplicated rows. There is a number of ways to do this, but I personally enjoy using the ROW_NUMBER() function for this. It is a clean and simple solution.SELECT orderId,
ROW_NUMBER() OVER(PARTITION BY orderId ORDER BY orderId) AS rowNum
FROM dbo.Orders;
The ROW_NUMBER() function here will now give a row number to each record in a window that is determined by the orderId column. As seen below:
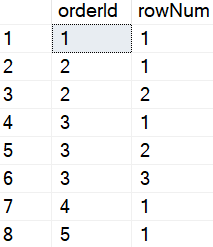
The ROW_NUMBER() function was used to derive the column rowNum in the above table. We can see that the ROW_NUMBER() function is used to count the number of rows with the same orderId. This is useful for us because we can use this method to identify which records would be duplicated records. Basically, records with a rowNum greater than 1 can be considered duplicated rows.
So now knowing this, we can use the ROW_NUMBER() function in a CTE (common table expression) and follow it up with a DELETE statement to remove the duplicated rows. As seen below:
WITH cte AS
(
SELECT orderId,
ROW_NUMBER() OVER(PARTITION BY orderId ORDER BY orderId) AS rowNum
FROM dbo.Orders
)
DELETE FROM cte
WHERE rowNum > 1;
After running this query, the Orders table looks like this:
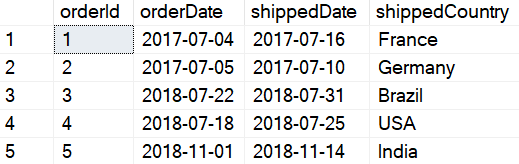
All the duplicated data for orderId 2 and 3 have been removed successfully.
Now, what if the DELETE statement is taking too long to execute? How do we fix this?
I shall speak about that in my next email, stay tuned!
So what if the DELETE statement takes too long to execute???